728x90
난이도 : 골드5
풀이일 : 2404243
https://www.acmicpc.net/problem/15486
15486번: 퇴사 2
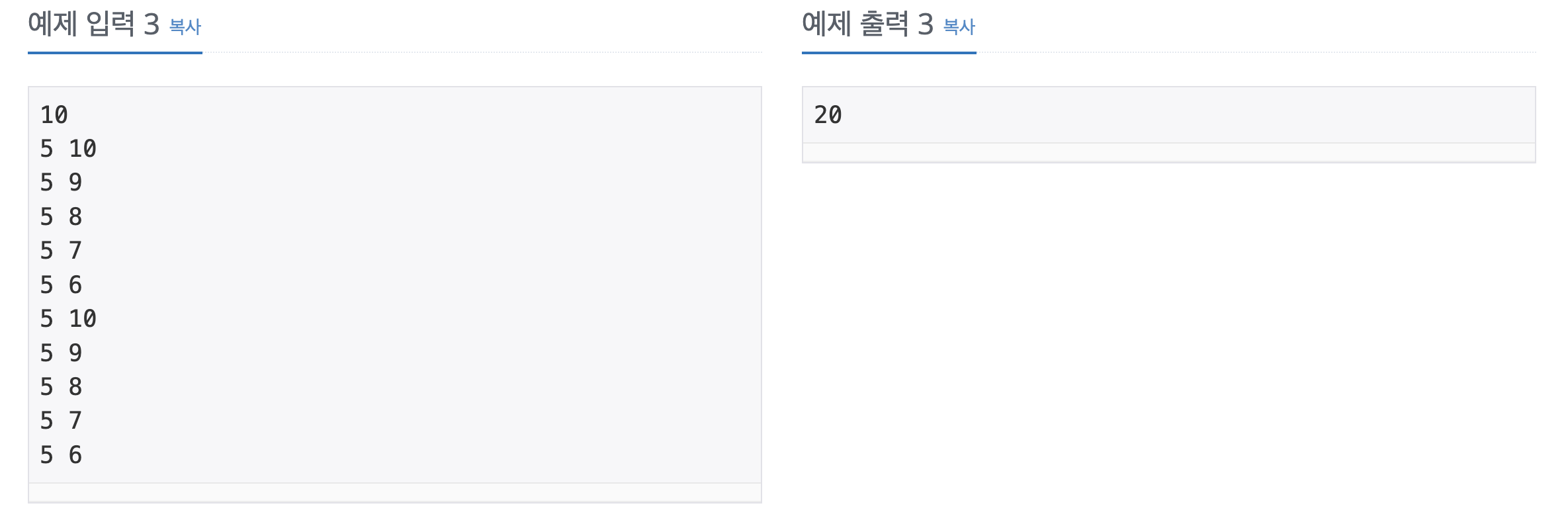
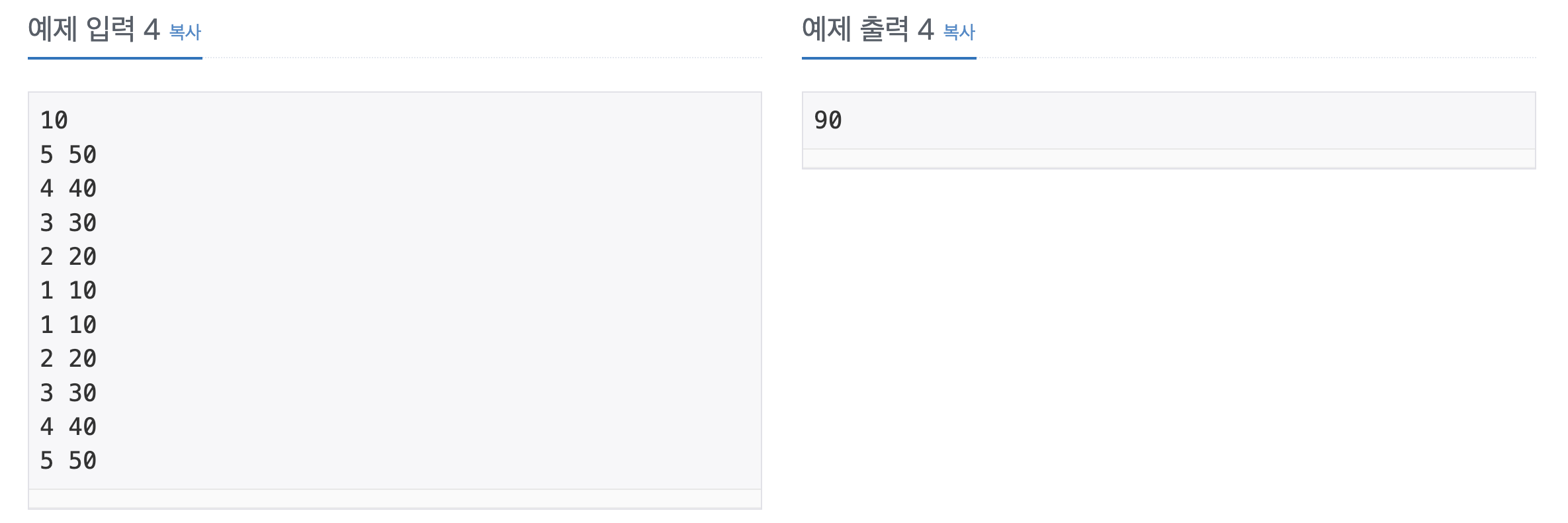
첫째 줄에 N (1 ≤ N ≤ 1,500,000)이 주어진다. 둘째 줄부터 N개의 줄에 Ti와 Pi가 공백으로 구분되어서 주어지며, 1일부터 N일까지 순서대로 주어진다. (1 ≤ Ti ≤ 50, 1 ≤ Pi ≤ 1,000)
www.acmicpc.net
문제 캡쳐

전체 풀이코드
import sys
N = int(sys.stdin.readline())
counsel = [(0, 0)] # 상담정보
dp = [0] * (N + 1) # 각 일자의 최고 금액
for _ in range(N):
day, money = map(int, sys.stdin.readline().split())
counsel.append((day, money))
for i in range(1, N + 1):
day, money = counsel[i]
# 현재 저장된 값과 이전 값 중 큰 값을 현재 최대 금액에 재할당
dp[i] = max(dp[i], dp[i - 1])
# 퇴사일 전에 해결할 수 있는 상담일 경우,
# 현재 상담 완료 시 금액과 이미 저장되어 있는 최대 금액 비교 후 큰 값 저장
if i + day <= N + 1:
dp[i + day - 1] = max(dp[i + day - 1], dp[i - 1] + money)
# 저장된 값 중 가장 큰 값 출력
print(max(dp))상세 풀이코드
N = int(sys.stdin.readline())
counsel = [(0, 0)] # 상담정보
dp = [0] * (N + 1) # 각 일자의 최고 금액
for _ in range(N):
day, money = map(int, sys.stdin.readline().split())
counsel.append((day, money))- counsel : 각 일자에 시작할 수 있는 상담의 소요기간과 금액을 저장합니다. 향후 내용을 변경하지 않을 것이므로, 성능을 위해 튜플을 사용하였습니다.
- dp : 각 일자까지 벌 수 있는 최고 금액을 저장할 배열입니다. 0일부터 N일까지의 정보를 저장합니다.
- for 반복문 : 주어지는 상담 소요 기간, 금액 정보를 counsel 배열에 저장합니다.
for i in range(1, N + 1):
day, money = counsel[i]
# 현재 저장된 값과 이전 값 중 큰 값을 현재 최대 금액에 재할당
dp[i] = max(dp[i], dp[i - 1])
# 퇴사일 전에 해결할 수 있는 상담일 경우,
# 현재 상담 완료 시 금액과 이미 저장되어 있는 최대 금액 비교 후 큰 값 저장
if i + day <= N + 1:
dp[i + day - 1] = max(dp[i + day - 1], dp[i - 1] + money)
# 저장된 값 중 가장 큰 값 출력
print(max(dp))- for 반복문은 1일부터 N일까지 반복하기 위해 (1, N + 1) 범위를 설정해줍니다.
- day, money : 해당일자에 시작할 수 있는 상담 소요 기간과 금액을 저장합니다.
- dp[i] : 현재 일자에 저장되어 있는 최고 금액과 어제까지 저장된 최고 금액 중 큰 값을 새로운 오늘 최고 금액으로 저장합니다.
- if i + day <= N + 1 : 만약 해당 상담을 퇴사 일 전에 끝마칠 수 있는 경우라면, 현재 상담을 완료하였을 때 일자의 dp 배열에 저장된 최대 금액과, 현재 상담을 완료하였을 때 최대 금액을 비교하고, 더 큰 값을 저장합니다.
- dp에 저장되어 있는 값 중 가장 큰 값을 출력합니다.
개선 과정
- 변수의 일부를 수정하였습니다.
- 최초 풀이 시 2차원 배열 dp를 사용했다가 메모리 초과를 받은 뒤, 통과된 코드들의 개선 과정입니다.
1차
import sys
N = int(sys.stdin.readline())
counsel = [[0, 0]]
total = [0] * (N + 1)
for _ in range(N):
day, score = map(int, sys.stdin.readline().split())
counsel.append([day, score])
for i in range(1, N + 1):
day, score = counsel[i]
total[i] = max(total[i], total[i - 1])
if i + day <= N + 1:
total[i + day - 1] = max(total[i + day - 1], total[i - 1] + score)
print(max(total))- day, score 를 리스트 형식으로 저장합니다.
2차
import sys
N = int(sys.stdin.readline())
counsel = [(0, 0)]
total = [0] * (N + 1)
for _ in range(N):
day, score = map(int, sys.stdin.readline().split())
counsel.append((day, score))
for i in range(1, N + 1):
day, score = counsel[i]
total[i] = max(total[i], total[i - 1])
if i + day <= N + 1:
total[i + day - 1] = max(total[i + day - 1], total[i - 1] + score)
print(max(total))- day, score를 튜플 형식으로 저장하여 성능을 개선하고자 하였습니다.
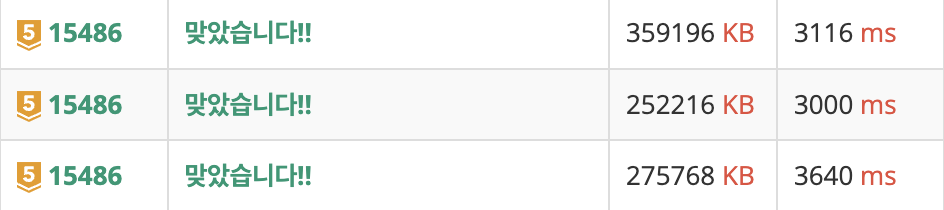
- 2차 코드와(위) 1차 코드(아래)의 실행 결과는 아래와 같습니다.

3차
import sys
lines = sys.stdin.readlines()
N = int(lines[0])
counsel = [(0, 0)]
dp = [0] * (N + 1)
for line in lines[1:]:
day, score = map(int, line.split())
counsel.append((day, score))
for i in range(1, N + 1):
day, score = counsel[i]
dp[i] = max(dp[i], dp[i - 1])
if i + day <= N + 1:
dp[i + day - 1] = max(dp[i + day - 1], dp[i - 1] + score)
print(max(dp))- total 대신 알고리즘 풀이방식인 dp로 변수명을 변경하였습니다.
- 여전히 시간이 너무 많이 나오는 것 같아서 입력방식을 바꿔보았습니다.
- lines에 전체 입력을 저장하고 쪼개서 쓰는 방식을 사용해보았는데, 자바처럼 느껴졌어요. 처음 사용해본 방식이라 재미있었지만 결과는 별로 좋지 않았습니다. 저장된 line을 불러와 사용하는 과정에서 메모리와 시간이 더 쓰여서 그렇다고 생각했습니다.
- 3차 코드(위) 부터 1차 코드(아래)까지의 결과는 아래와 같습니다.
4차
import sys
N = int(sys.stdin.readline())
counsel = [(0, 0)]
dp = [0] * (N + 1)
for _ in range(N):
day, score = map(int, sys.stdin.readline().split())
counsel.append((day, score))
for i in range(1, N + 1):
day, score = counsel[i]
dp[i] = max(dp[i], dp[i - 1])
if i + day <= N + 1:
dp[i + day - 1] = max(dp[i + day - 1], dp[i - 1] + score)
print(max(dp))- 문제에 맞추어 score 변수를 money로 수정하였습니다.
- 입력 방식을 다시 처음처럼 수정하였습니다.
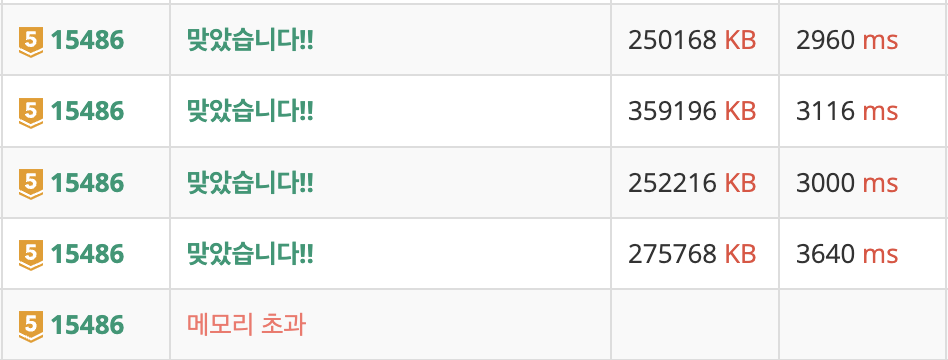
- 4차 코드(가장 위) 부터 1차 코드 이전 실패코드(가장 아래)의 실행결과는 아래와 같습니다.
느낀점
- 처음에 너무 복잡하게 접근하여 조건 분기를 많이 했었는데, 비효율적이고 메모리를 너무 많이 사용하는 방식이었습니다.
- 어쩐지 dp는 잘 익숙해지지 않는 것 같아, 조금 더 자주 문제를 풀고 풀이 방식에 익숙해지겠다고 다짐했습니다.
- 기초가 되었던 자료형들을 적절히 가져다 쓸 수 있도록 한 번 더 복습할 필요성이 있다고 느꼈습니다.
'알고리즘 > 🥇 골드' 카테고리의 다른 글
| 백준 14567 선수과목 (Prerequisite) 파이썬 풀이 (1) | 2024.05.01 |
|---|---|
| 백준 7579 앱 파이썬 풀이 (0) | 2024.04.25 |
| 백준 2470 두 용액 파이썬 풀이 (1) | 2024.04.22 |
| 백준 1976 여행 가자 파이썬 풀이 (0) | 2024.04.17 |
| 백준 13023 ABCDE 파이썬 풀이, 반례 (0) | 2024.04.15 |



